
Innehåll
Tillsammans med sin nya Mali-G77 grafikprocessor och Mali-D77-skärmprocessor har Arm avslöjat sin senaste högpresterande CPU-design - Cortex-A77. Precis som förra årets Cortex-A76, är Cortex-A77 designad för premium-nivåer applikationer som kräver Arm signatur låg effektförbrukning. Allt från smartphones till bärbara datorer och ganska troligtvis bortom.
Med Cortex-A77 har Arm riktat in sig på den maximala instruktionen per cykel / klocka (IPC) prestationsökning som den skulle kunna hantera över Cortex-A76. Klockfrekvenser, energiförbrukning och område är alla utformade för att förbli ungefär i samma bollplats, men den nya kärnan kan sprida igenom mer instruktioner på en gång. För att göra detta har Arm designat en ännu bredare kärna än förra året och har gjort ett antal förbättringar för att hålla CPU-kärnan matad med saker att göra. Men innan vi kommer till det, låt oss dyka in i översiktsnivån och prestandanummer.
Att träffa prestandamål
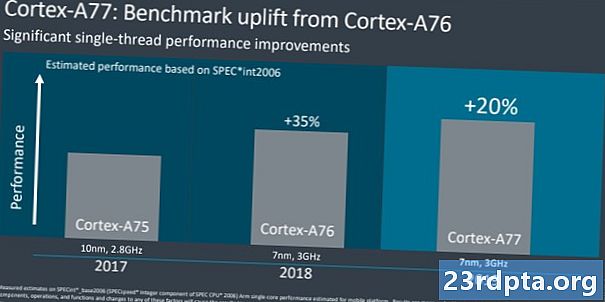
Tillbaka i augusti 2018 delade Arm karaktäristiskt en CPU-färdplan fram till 2020. Från 2016: s Cortex-A73 till 2020: s "Hercules" -design, lovar företaget en 2,5x ökning av datorprestanda. En rättvis bit av denna enorma projektion åstadkoms med den stora mikroarkitekturskiftet med Cortex-A76, högre moderna klockhastigheter och flytten från 16 till 10 och nu 7nm tillverkning med 5nm att följa. Cirka 1,8x av färdplanens vinster uppnåddes redan förra året, och Cortex-A77 ger cirka 20 procent ytterligare IPC-boost. Detta sätter oss väl på väg mot Arm's 2,5x mål, även om mobila enheter med begränsad effekt och termiska budgetar inte förväntar sig att se alla dessa vinster.
Som jämförelse, förra årets Cortex-A76 gav cirka 30-35 procent ökning jämfört med Cortex-A75. I år tittar vi på en mer dämpad, men ändå betydande, 20 procent IPC-vinst mellan A77 och A76. Det här är goda nyheter eftersom det betyder mer prestanda medan du håller dig till liknande termiska och effektbegränsningar som tidigare. Avvägningen är att A77 är cirka 17 procent större än A76, så det kommer att kosta lite mer vad gäller kiselområdet. Om du vill ha en jämförelse med skrivbordsledarna lyckades AMD ha en 15-procentig IPC-boost mellan Zen2 och Zen +, medan Intels IPC har förblivit praktiskt taget statiskt i flera år.Naturligtvis talar vi olika marknadssegment här, men det visar hur Arm's CPU-designteam har gjort imponerande vinster under de senaste generationerna.
Ett 20% prestationsökning erbjuds för nästa gen Cortex-A77 baserade SoC: er
Avhämtningen här är att A76 markerade en stor mikroarkitektonisk förändring med enorma prestandaförmåga, medan vi är tillbaka till optimeringsnivåförbättringar med A77. Med det ur vägen, låt oss dyka in i det som är nytt i Arm Cortex-A77.
Cortex-A77 bygger på mikroarkitekturen A76
Nyckeln till att förstå skillnaden mellan Cortex-A77 och A76 är att förstå vad som menas med en ”bredare” kärndesign. I huvudsak talar vi förmågan att utföra fler instruktioner för varje klockcykel, vilket ökar kärnans kapacitet. Det finns två viktiga delar för att få detta rätt - öka antalet exekveringsenheter för att bearbeta och se till att dessa enheter hålls väl matade med data. Låt oss börja med den senare delen och fokusera i avsändnings-, cache- och grenprediktordelarna i SoC.
Cortex-A77 ser en 50-procentig ökning för att skicka bredd, upp till sex instruktioner per cykel från fyra med A76. Det betyder fler instruktioner som går till exekveringskärnan för varje klockcykel för större prestandapotential. Exekveringsfönstret utanför ordningen är också större som ett resultat och ökar till 160 poster för att avslöja mer parallellitet. Det finns en bekant 64K-instruktionscache, medan Branch Target Buffer (BTB), som har adresser för grenprediktorn, är 33 procent större än tidigare för att hantera tillväxten i parallella instruktioner. Inget ovanligt här, det är i huvudsak en bredare version av förra årets design.
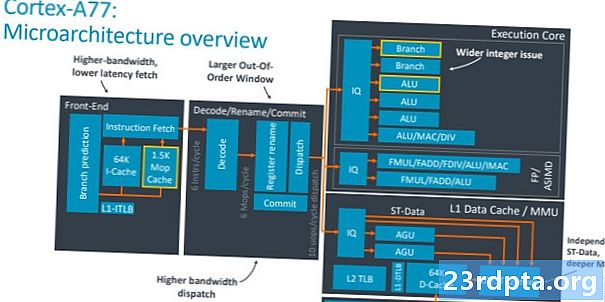
Det mer spännande fronttillägget är den helt nya 1.5K MOP-cachen, som lagrar makro-Ops (MOP) som matas tillbaka från avkodningsenheten. Arm's CPU-arkitektur avkodar instruktioner från en användares applikation till mindre makrooperationer och sedan ner till mikro-ops som exekveringskärnan förstår. Du kan se detta på diagrammet ovan i avkodningsavsnittet. MOP-cachen används för att minska kostnadsstraffet för missade grenar och flusher, eftersom du håller i makrooptioner snarare än att avkoda dem igen och ökar kärnans totala genomströmning. Hämtar från MOP istället för i-cache förbi avkodningssteget och sparar en cykel. Arm säger att MOP-cachen kan träffa 85% eller mer träfffrekvens över en mängd arbetsbelastningar, vilket gör det till ett mycket användbart tillägg till standard i-cache.
Flytta ner till processorns kärndel av CPU, notera tillägget av en fjärde ALU och andra Branch-enhet. Denna fjärde ALU ökar processorns allmänna antal som krossar bandbredd med 50 procent. Denna ytterligare ALU är kapabel till grundläggande enhetscykelinstruktioner (som ADD och SUB) plus tvåcykliska heltalstjänster som en sådan multiplikation. Två av de andra ALU: erna kan bara hantera grundläggande encykelinstruktioner, medan den slutliga enheten laddas med mer avancerade matematikoperationer som division, multiplicera ackumulering, etc. Den andra grenenheten i exekveringskärnan fördubblar antalet samtidiga grenhoppar kärnan kan hantera, vilket är användbart i fall där två av de sex skickade instruktionerna är grenhopp. Detta låter lite konstigt, men interntest hos Arm avslöjade prestandafördelar med att använda den andra enheten.
Cortex-A77 erbjuder förbättrad parallellitet och en ny ansträngning för att hämta cachar
Andra justeringar till CPU-kärnan inkluderar tillägget av en andra AES-krypteringsrörledning. Pipelinjerna i datalageret har nu dedikerade problemportar för att fördubbla bandbredden för minnesfrågan. Dessa portar delades tidigare med ALU: erna, som ibland kan bli en flaskhals. Det finns också en nästa generations dataprofekt för att förbättra energieffektiviteten och samtidigt öka bandbredden till system DRAM.
En del av detta system i Cortex-A77 har också ett helt nytt ”systemmedvetet” prefetch-system. Detta förbättrar minnesprestanda baserat på det stora utbudet av CPU-kärnantal, cachekapacitet och latenser och minnesundersystemskonfigurationer i slutliga enheter. Den dedikerade hårdvaran för att prata med Dynamic Scheduling Unit (DSU) som en del av ett DynamIQ CPU-kluster, som övervakar användningen av den delade L3-cachen. Kärnan har dynamiska avstånds- och aggressivitetsnivåer för att minska cacheutnyttjandet i situationer där L3-bandbredd begränsas av andra CPU-kärnor. Kärnor med högre prestanda som Cortex-A77 är mer benägna att mätta DSU-åtkomst till minne, medan kärnor med lägre effekt som A55 inte är troliga.

Passar allt tillsammans
Det finns massor av små förändringar i Cortex-A77 som lägger till några väsentliga skillnader till dess föregångare. I ett nötskal hjälper A77: s nya MOP-cache i kombination med ett bredare och längre instruktionsfönster att hålla den förstärkta ALU-, Branch- och minnesenheten upptagen med saker att göra. Kraftverkets Cortex-A76-design har utvidgats för att förbättra produktionen ytterligare med A77, utan att förlita sig på högre klockhastigheter.
Den största föreställningen ökar till att Cortex-A77 anländer i form av ett heltal och flytande punktmatematik. Detta bekräftas av Arm: s interna riktmärken, som visar en prestationsökning på 20 till 35 procent i SPEC-heltal respektive flytande punkt. Förbättringar av minnesbandbredden sitter någonstans mellan 15 och 20 procent, vilket återigen framhäver att de största vinsterna kommer i form av siffror. Sammantaget ger dessa förbättringar A77 en genomsnittlig höjning av 20 procent jämfört med föregående generation. Vi kan också se några ytterligare, mer marginella vinster till följd av mer avancerade tillverkningsprocesser på 7 nm senare i år eller i början av 2020.
När det gäller smartphones är Cortex-A77-driven SoC: er avsedda för högpresterande flaggskeppsprodukter. Arm förväntar sig att se kraftverk design med 4 + 4 bit.LITTLE kärnarrangemang. Med tanke på den ökade genomströmningen och den lilla bult till areastorleken på A77 kommer vi förmodligen se att SoC-designers fortsätter nedåt 1 + 3 + 4 eller 2 + 2 + 4-trenden. Med en eller två kraftfulla stora kärnor med större cacher och högre klockor, säkerhetskopierade med 2 eller 3 A77-kärnor med mindre cache-storlekar och lägre klockor för att spara på kraft och område. I slutändan stavar Cortex-A77 bra saker för smartphonechips och den växande marknaden för alltid anslutna armbaserade bärbara datorer. Håll utkik efter kiselmeddelanden senare i år.


